

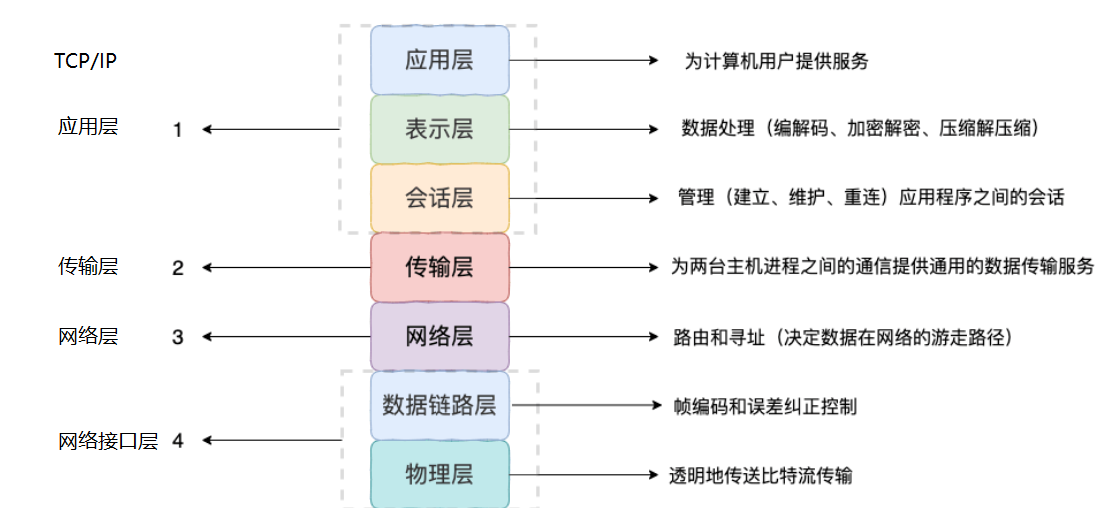
网络分层模型及各层功能
网络分层模型
OSI七层模型与TCP/IP4层模型

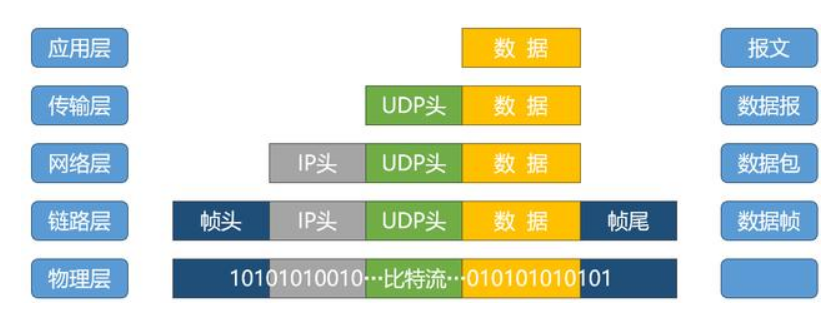
报文、数据报、数据包、帧的区别
数据的封装
网络接口层
- 网卡
- 将接收的电信号转为数字信号,并封装为数据帧。
- 通过 DMA(直接内存访问) 将数据直接写入内核指定的内存缓冲区(临时存储所有传入的原始网络数据包)
- 内核的网络协议栈对数据包解封装,直到传输层解封后获得端口信息
- 如果是SYN包,连接成功后将数据转发到监听目的端口的socket的内核缓冲区
- 否则,通过数据包4元组找到对应的socket,并把数据转发到对应的内核缓冲区
IP层:对数据包进行路由和寻址
IP报文
- 源ip/目的ip地址:如果有nat,会修改ip协议的源ip/目的ip地址,否则传输时一直不变
- IP分片/重组:通过标识字段与片偏移字段来实现
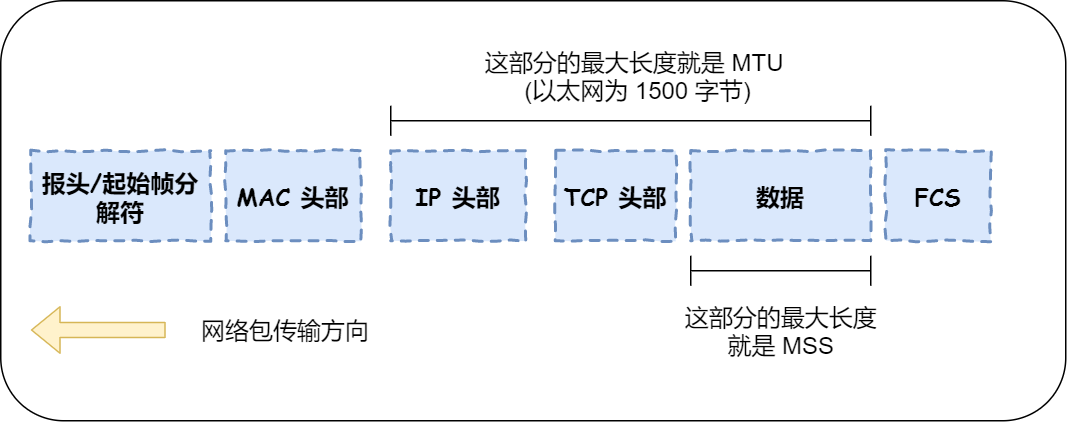
- tcp数据报一般不会被ip分片,tcp建立连接时会确认传输路径所有结点的ip包最大长度(MTU),保证不会被分片(如果存在有结点的MTU变小,则会返回icmp确认最小的MTU,避免分片)
- upd数据报过大就会被分片,只有第一个片段有udp头部
常见的IP协议
- ICMP:ip传输出错时(网络层错误,无需端口号),用于告知网络包传送过程中产生的错误以及各种控制信息(目标不可达、超时、路由重定向)
- NAT(Network Address Translation,网络地址转换)的作用:在不同网络之间转换 IP 地址
- ARP(Address Resolution Protocol,地址解析协议):将IP解析为MAC地址
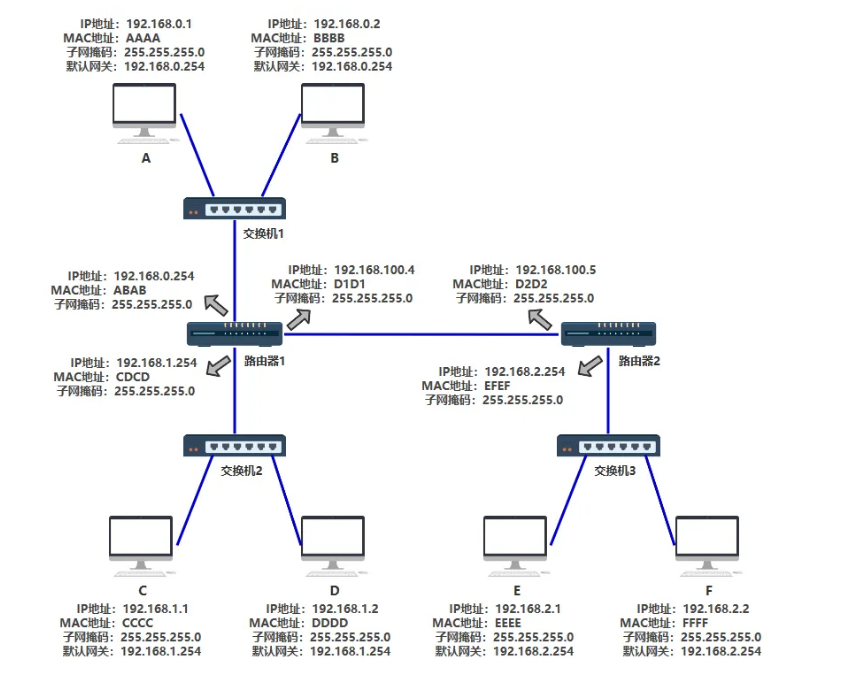
数据包如何在网络中传输与定位:IP与MAC地址
- 基本网络设备
- 交换机:一般与子网内的所有计算机/路由器连接。维护MAC地址表,记录交换机的每个端口连接的计算机设备的MAC地址
- 路由器:路由器每个端口都有一个独立的MAC地址和IP地址,每个端口指向一个子网。维护路由表,映射ip地址对应哪个端口
- 计算机:每个计算机设备都有唯一的MAC地址,加入网络时,会分配一个ip地址与相应的子网掩码,并指定其默认网关(子网的路由器对应端口的ip)
- 数据包传输流程(MAC头部每到一个结点就需要重新封装,设定当前设备MAC为源MAC,下一个设备为目标MAC)
- 电脑封装完ip数据包后,通过子网掩码判断目标ip是否同一个子网
- 是则使用ARP协议获取MAC地址,并通过交换机传输到目标计算机
- 否则使用ARP协议获取默认网关的MAC地址,通过交换机传输给默认网关去转发
- 路由器的A端口收到数据包后,查询路由表确认从B端口转发出去,B端口需要更新数据包的目的MAC地址:与目标主机同一子网则获取其MAC,否则是默认网关的MAC
- 电脑封装完ip数据包后,通过子网掩码判断目标ip是否同一个子网
传输层
- 传输层用于确保进程到进程之间的数据交互(端到端),因此传输层协议引入了端口的概念,用于区分同一个传输层协议下应该把数据包发送给哪个进程的socket
- 传输层的协议通过源/目的ip、端口来分别一个连接
- 不同协议的端口互不影响
- 同一个端口(要求未被某个进程给bind独占了)可以向不同的ip:port发起connect,只要四元组不冲突即可
TCP 与 UDP 的区别
- TCP是否面向连接的,是可靠传输,是有状态的,UDP不是
- TCP传输的时候多了连接、确认、重传等机制,效率低
- TCP 是面向字节流的(将应用层报文以字节流划分为多个tcp段,每个段都有自己的tcp头部)
- UDP 是面向报文的(应用层报文只用一个upd头部修饰,分片交给ip)
TCP
TCP报文
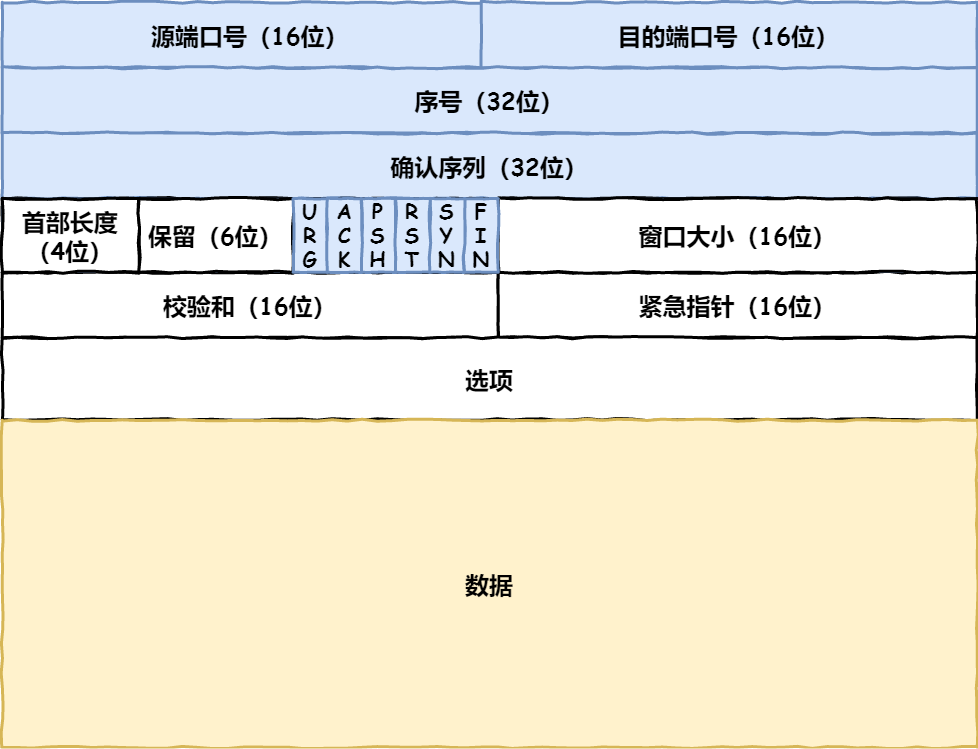
- 标志位
- ACK :确认号,表示下一个接受的包的SEQ值
- SYN :同步序列号,用于建立连接,会携带初始序列号(ISN,一个随机数(基于时钟计时器递增),避免阻塞的旧历史报文被新连接接受)
- RST :出现异常,要求接收方强制关闭连接
- RST包被接收的前提是ack的序列号是对方接收的合法序列号
- FIN :发送方不再有数据需要发送,请求终止连接
三次握手
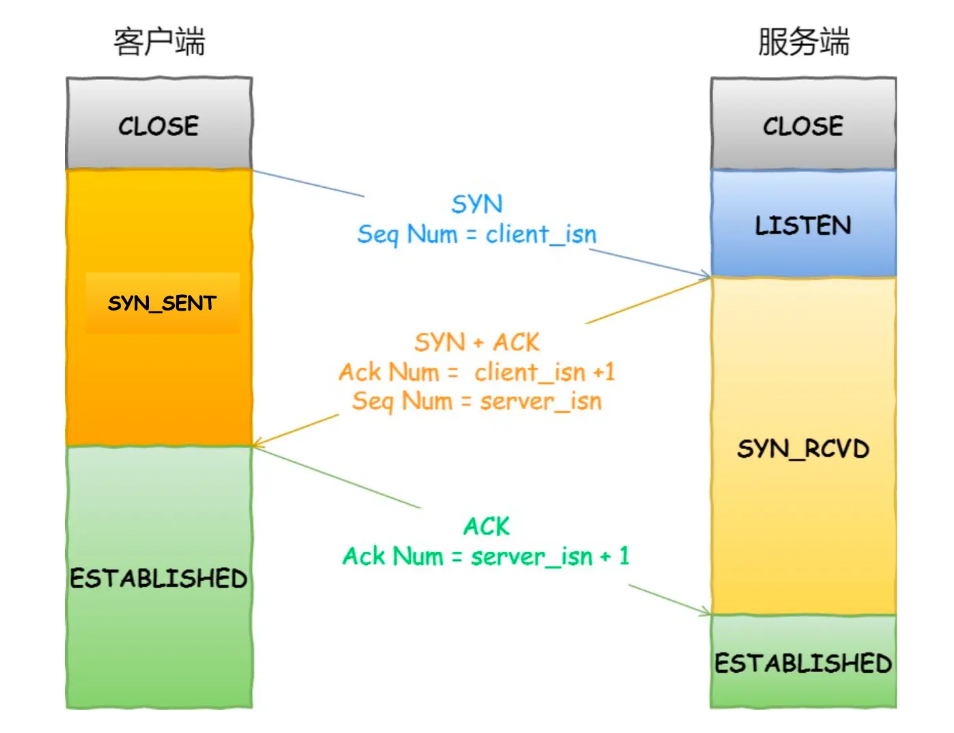
- 流程
- 一次握手:客户端发送带有 SYN(SEQ=x) 标志的数据包到服务端,然后客户端进入 SYN_SEND 状态,等待服务端的确认
- 二次握手:服务端发送带有 SYN-ACK(SEQ=y,ACK=x+1) 标志的数据包到客户端,然后服务端进入 SYN_RECV 状态;
- 服务端内核同时把该连接放入半连接队列
- 三次握手:客户端发送带有 ACK(ACK=y+1) 标志的数据包(可以携带传输数据)到服务端,然后客户端进入ESTABLISHED 状态,服务端接收后也进入ESTABLISHED 状态; TCP 三次握手完成
- 服务端内核同时把该连接从半连接队列移动到全连接队列,等待后续socket调用accept函数处理
- 三次握手的意义
- 确保双方都ack了对方的初始序列号 :1,2步确认服务端可接收客户端消息;2,3步确认客户端可接受服务端消息
- 防止网络阻塞时,重传的多个SYN包均被建立连接并初始化了
- 如果是一次握手后服务端就直接进入ESTABLISHED状态,并被分配资源。但是这个连接实际是历史连接(后续的syn连接才是新连接)
- 服务端中间态SYN_RECV发送的SYN+ACK包,如果ack的不是当前服务端请求的syn包,则客户端会发送RST包终止这个半连接
- SYN Flood攻击
- 短时间伪造不同 IP 地址的 SYN 报文,占满服务端半连接队列导致正常连接无法建立
- SYN Cookies策略(无状态SYN)
- 队列占满时,不再分配资源来保持新连接状态
- 根据四元组,以及一个只有服务器知道的密钥来计算哈希值作为SYN包的序列号并发送SYN-ACK包
- 客户端回复ACK时,服务端再次计算出该哈希值,若ack序列号与计算的一致则建立连接
四次挥手
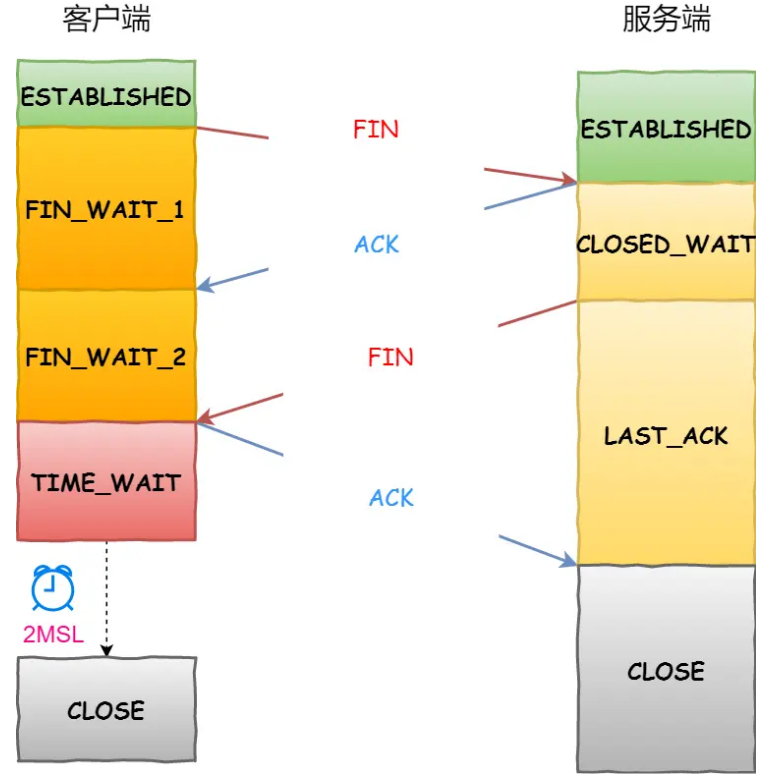
- 流程(前2次挥手是说明客户端不会再有消息需要发送,后2次挥手是为了说明服务器不会再有消息发送 ;双方都可以主动断开,但是一般会由服务端结束服务后直接断开,减少监听到断开请求再close的损耗)
- 第一次挥手:发送方调用close函数,并发送一个 FIN(SEQ=x) 标志的数据包到接收方,表示其不再有数据传输,然后发送方进入 FIN-WAIT-1 状态
- 第二次挥手:接收方发送一个 ACK (ACK=x+1)标志的数据包到发送方,然后进入 CLOSE-WAIT 状态。发送方收到后进入 FIN-WAIT-2 状态。
- 不同时发送SEQ,是因为接收方可能还有数据未传输完,所以第三次挥手再确认。
- 第三次挥手:接收方调用close函数,并发送一个 FIN (SEQ=y)标志的数据包到发送方,然后进入 LAST-ACK 状态
- 第四次挥手:发送方发送 ACK (ACK=y+1)标志的数据包到接收方,然后进入TIME-WAIT状态。接收方在收到 ACK (ACK=y+1)标志的数据包后进入 CLOSE 状态。
- 此时如果发送方等待 2MSL(Maximum Segment Lifetime,报文最大生存时间) 后依然没有收到回复,就证明接收方已正常关闭,随后发送方也可以关闭连接了(发送方等待防止server为收到ack持续fin确认)。发送方每次接收到接收方的FIN包,都会重置定时器
- 2MSL的目的是确保ack发送过去后(最多消耗1msl),如果ack未到达,会接收到重传的fin包(又是最多1msl)
- 保证了超过2msl时直接关闭连接,网络上该tcp连接的报文都被丢弃了,防止旧报文被后续的新tcp连接接收
- 服务端time_wait的情况(主动断开tcp连接)
- http没有使用长连接,每次http响应结束则主动断开tcp
- http长连接超时 :如果指定时间内,http长连接不再有请求,则会主动断开
- http长连接的请求总数量达到上限(每条长连接都是有指定可处理多少次请求)
- 服务端出现close_wait的情况(客户端主动断开)
- 建立连接的tcp,没有成功调用accept函数获取socket(或者获取了但是没有成功注册到epoll),导致客户端超时主动断开,但是服务端因为没注册socket到epoll并未感知到
- 进入close_wait后服务端未成功调用close函数
TCP 传输可靠性保障(校验和、重传机制、流量控制、拥塞控制)
- 流量控制(滑动窗口实现,控制发送方发送速率,保证接收方来得及接收)
- 滑动窗口还有空间时,发送方无需等待ack,可以继续发送数据
- 每次以收到的最大ack来移动窗口
- 当接收窗口为0,又一直未接收到接收窗口的恢复,发送方会定时进行接收窗口大小的探测
- 发送方每次会根据剩余接收窗口的大小,来制作下一个不大于MSS大小的数据包并发送
- 拥塞控制:慢启动(指数递增)、拥塞避免(线性增长),流程如下:
- 发送方的窗口大小取决于:接收方允许的窗口和拥塞窗口
- 当拥塞窗口(CWND)达到或超过拥塞避免阈值(ssthresh) 时,cwnd改为ssthresh,TCP会从慢启动阶段转入拥塞避免阶段。
- 数据包超时说明发生网络拥塞(或者根据计算的RTT往返时延来判断),拥塞避免阈值会重新调整为当前拥塞窗口的一半(即减小),拥塞窗口重新设置为1,进入慢启动
- 快速恢复 :发生三次重复 ACK,将 ssthresh和CWND调整为当前 CWND 的一半,进入拥塞避免阶段
- 重传机制
- 超时重传:发送的数据包同时会启动一个定时器,规定时间为收到相应ack,触发重传,每次重传间隔增大(指数退避),多次重传仍未收到ack则关闭连接
- 快速重传:收到多个重复ack(3个以上),则重传ack所需数据包
- sack(选择性确认) :如果有缺失数据包,该字段会声明后面接收到的数据包,这样快速重传可以把前面缺少的数据包都重传
TCP的一些可选机制
- TCP保活机制(keepalive)
- keepalive机制
- 如果在tcp_keepalive_time内(默认2h)都没有任何数据交互,会触发keepalive
- 会进行tcp_keepalive_probes(默认9次)次探测,每次间隔tcp_keepalive_intvl(75s),如果对方一直没有对探测响应,则关闭该连接
- 当接收到数据时,保活时间都会被重置
- 默认都会在上层实现keepalive逻辑(并在应用层结束时关闭tcp),而不是直接使用tcp的keepalive
- keepalive机制
socket套接字
- socket是os对网络端到端通信的节点的封装(抽象为一个文件描述符fd,用于网络节点通过socket进行数据交换)
- 服务端socket
- 监听socket :将创建的socket bind到指定端口,即可调用listen监听
- 当客户端连接请求经过传输层协议后,便会被内核记录为io事件并通知监听socket处理
- 监听socket调用accept处理连接事件,创建新的socket用于与客户端数据通信
- 数据通信socket :由源/目的端口、ip这个4元组唯一标识。应用层通过该socket来进行数据读写
- 监听socket :将创建的socket bind到指定端口,即可调用listen监听
- 客户端socket :创建的socket将指定ip:port进行connect,成功后即可通过该socket进行数据读写
- 服务端socket
应用层
DNS解析(nslookup 命令):域名存在于应用层,属于应用层协议
- A/AAAA :将域名解析为IPv4/IPv6地址
- CNAME :将域名作为别名指向另一个域名,与其保持相同解析
- PTR :DNS反解析,将ip解析为域名
HTTP(无状态协议)
HTTP字段
- GET 和 POST 的区别
- GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
- GET 请求是幂等的,即多次重复执行不会改变资源的状态(该请求可以缓存,无副作用),而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
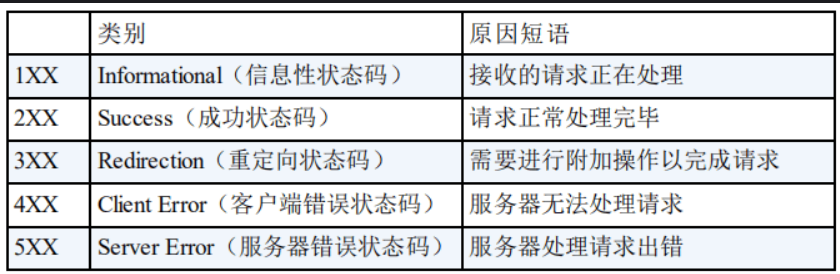
- HTTP 状态码
- 301,302 :永久/临时重定向,会指明新url,由浏览器自动跳转
- 304 :Not Modified,请求资源未修改,可直接使用缓存
- 502 :请求路径上存在服务器无法得到其上游服务器的有效响应,存在网络错误
- 503 :服务器繁忙,当前无法响应
- 常见HTTP请求头/响应头
- Content-Type :声明请求/响应体的数据类型,如application/json(json),text/plain; charset=UTF-8(utf8编码的纯文本)
- ETag :用于唯一标识请求资源
- If-None-Match :用于缓存验证,会把之前请求资源的ETag作为value发送给服务器,如果服务器检测ETag未变,则返回304
HTTP1.1:默认使用长连接(客户端可以建立tcp连接池来利用tcp长连接的特性)
- 单个TCP连接在同一时刻只能处理一个http请求,任意两个 HTTP 请求从开始到结束的时间在同一个 TCP 连接里不能重叠。
- 在应用层方面存在队头阻塞问题:同一tcp下的http请求,队头阻塞,后面请求都需要等待
- 流水线(Pipelining)优化(默认不启用,实现复杂且效果不佳):在同一条长连接上发出连续的请求,无需等待响应。服务器需要按接收顺序依次处理请求,响应也必须按顺序返回。
- http1.1基于文本分割来解析,在遇到分隔符前不能停止解析,不适合划分成基本单位来实现多路复用
- 性能优化策略
- 通常采用连接复用(长连接)和同时建立多个TCP连接的方式提升性能。但浏览器对其访问的host域名可建立的TCP连接数有限制(6~8个)
- http的长连接长时间空闲一般会断开(长时间空闲浪费服务器资源)
- 域名分片(加速图片等大资源的获取速度):通过将内容拆分到多个子域来提高网页加载速度的技术,突破浏览器对同一域名host可以使用的tcp限制(从多个子域名获取资源,而这些子域名其实都指向同一台目标服务器,这样能并发使用更多tcp连接)
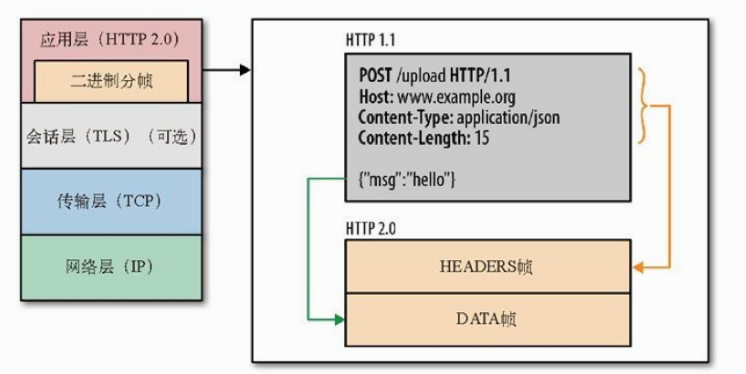
HTTP2:基于https上实现。基于二进制帧(紧凑的二进制结构)来传输数据,不再是明文传输
- 基本概念
- 帧(frame):最小的数据单位,帧包含数据长度、流标识符、帧类型等信息。http请求报文被拆散成帧
- 消息(message):即http报文(一个请求/响应),消息由帧组成(由头部帧和数据帧组成)
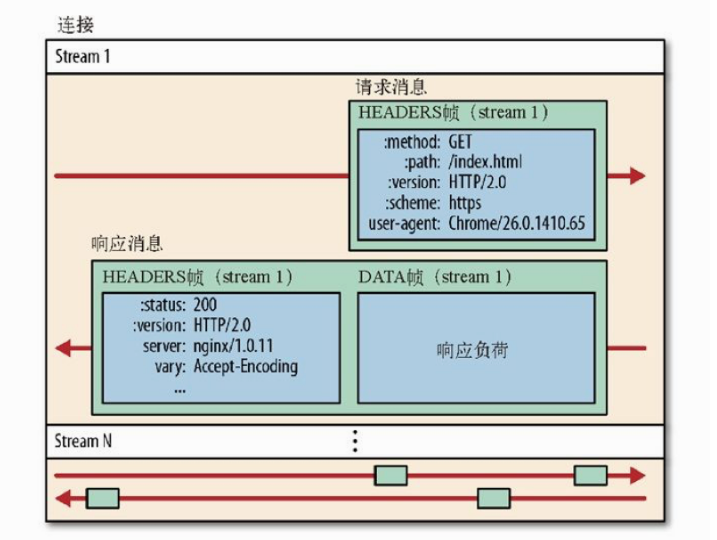
- 流(stream):一次完整的请求-响应由对应的流id标识,即流是双向的(含有一对请求消息+响应消息)
- 流id严格递增,不可复用,具有唯一性,其流id对应了一次请求-响应
- 一般规定客户端发起的流id奇数,服务端发起的流id偶数,避免冲突
- 同一个流发送的帧要有顺序,接受端按照收到帧的顺序重新组装成消息(http报文)
- 多路复用(Multiplexing,一个TCP段可以存在多条流)
- 同个域名只需要一个 TCP 连接,使用一个连接并行发送多个请求和响应。
- 一个tcp段会包含多个stream,一个stream可能会分成非连续多次发送。
- 不同流的帧之间可以乱序发送,因为会按照各自的流id组装
- 请求优先级:每个流可以设定优先级
- 流量控制:设定每个流可以占用一个tcp段多少带宽(接收端通过WINDOW_UPDATE帧控制其对应流的流量窗口大小),基于每一跳进行,而非端到端的控制
- 服务端推送:服务端响应时也可以使用新流推送(预加载)资源给客户端(可被拒绝),减少请求响应次数
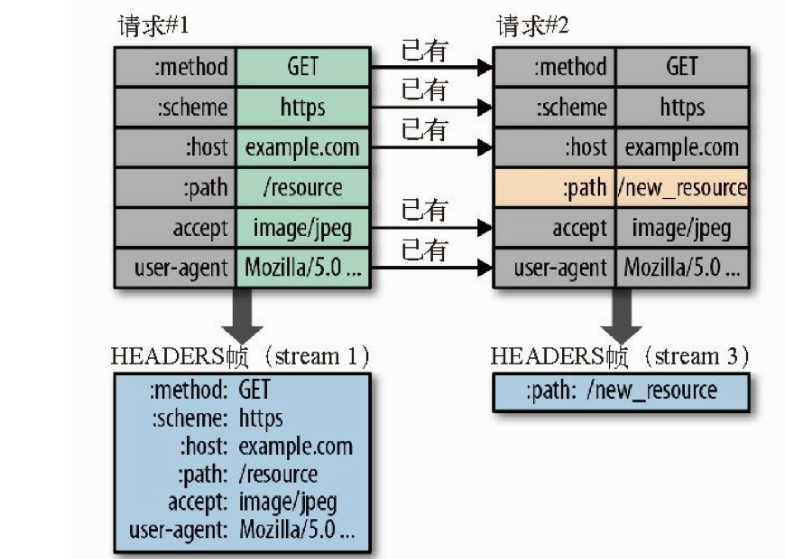
- 头部压缩(HPACK)
- 原因:http1.1只针对body进行压缩,而包含协议内容,cookie等字段的请求头,有很多内容重复却没有压缩
- HPACK 压缩算法
- 客户端和服务端共同维护了一份字典表,来跟踪和存储之前发送的键值对
- 每次发送数据时,相同的数据不再通过每次请求和响应发送;新数据/修改数据要么被追加到当前表的末尾,要么替换表中之前的值
- 禁用域名分片
- 破坏多路复用优势:分片强制使用多个连接,反而增加握手和头部冗余。
- 加剧头部压缩失效:多个子域名的请求需携带独立头部信息,无法充分复用HPACK字典。
- 缺点
- TCP层面的队头阻塞并没有彻底解决:“超时重传”机制,丢失的包必须重传确认,后面的TCP包必须等待
- 多路复用没有限制同时请求数,可能导致服务器压力上升
- 多路复用容易 Timeout: 大批量并行多个流,导致每个流的资源会被稀释,虽然它们开始时间相差更短,但却都可能超时
HTTPS(使用 SSL/TLS 协议用作加密和安全认证)
- SSL原理
- 非对称加密:发送方有公匙用于加密,接收方有私匙用于解密。安全性高,但代价高。用于传输对称加密密匙
- 对称加密:通信双方共享唯一密钥 k,加解密算法已知,双方利用密钥 k 加密/解密。代价低,但保密性差。用于传输数据
- CA证书:有CA数字签名的服务器合法,其公匙可信,不会被伪造,CA使用CA私匙对服务器的公匙加密附在证书中,把证书颁发给服务器
- https传输原理
- 客户端先获取服务器证书,使用CA公匙验签后获取服务器公匙(私匙加密,公匙解密用于验签)
- 客户端生成对称加密密匙,用服务器公匙加密后发送给服务器(公匙加密,私匙解密,用于传输密匙)
- 服务器用服务器私匙解密,获取对称加密密匙,以后双方使用该密匙通讯
URL(Uniform Resource Locators,即统一资源定位器)
- URL的组成结构
- 协议:URL的前缀采用了何种应用层协议:HTTP/HTTPS/FTP等
- 域名(DNS解析域名和ip地址的映射),端口, 资源路径
- 请求参数:采用键值对的形式key=value,每一个键值对使用&隔开
- 锚点:显示该网页页面的位置,锚点以#开头,且不会作为请求的一部分发送给服务端
- 从输入 URL 到页面展示的过程
- 在浏览器中输入指定网页的 URL,浏览器通过 DNS 协议(应用层),获取域名对应的 IP 地址
- 浏览器根据 IP 地址和端口号,使用socket向ip:port发起connect
- connect时会先进行tcp连接请求,成功后该连接被放入全连接队列并唤醒服务端的监听socket
- 服务端的监听socket处理连接事件并调用accept建立一个新socket负责与该客户端的通信
- connect成功后,浏览器对http请求报文层层封装,并发送到服务端
- 服务端内核解封数据包后通过四元组交由对应的socket处理
- 服务端应用层通过socket获取到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器
- 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示
- 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
