

Java基础知识随记
基础知识
Java访问修饰符为默认(default)是包级访问权限,只有包内的类才能访问,而不是public
Java只有值传递,不存在C++的引用传递
==比较值(基本类型的值是value,类的值是地址),equal的比较一般是内容相等(但是Object的equal是=比较)
hashCode()用于快速判断元素之间相等,减少equla调用。hash相等才用equal判断是否真相等而非hash冲突。
重写 equals() 时必须重写 hashCode() 方法
包装类保存的基本类型的值都是final,每次赋值都是重新new
String、StringBuffer、StringBuilder

- String的值是final,不可变,对其修改/拼接等操作是new String()给他指向
- String.intern():如果常量池中已经存在相同内容的字符串,则返回常量池中已有对象的引用;否则,将该字符串添加到常量池并返回其引用。
方法回调(CallBack):解耦逻辑、提高复用和可扩展性。思想如下
- 函数A执行需要调用函数B,对于B的执行结果,A会把相应的处理逻辑封装成函数接口(称为:回调函数)
- 在调用B时,A同时传递回调函数,B在执行时,会自己决定何时使用回调函数
- 好处是当多个不同函数调用B,各自实现自身的回调函数,即可复用函数B

注解(@interface)
常用注解
- @PostConstruct :标记方法,表示方法在依赖注入完成后需要立刻执行
- 用于字段均注入后,执行初始化工作(因为部分字段未在构造函数初始化,而是之后通过setter注入等)
枚举(Enum)
- enum代码块的执行顺序
- enum实例本质是静态final实例(即enum类的静态字段)
- 根据初始化时的顺序,先给静态字段赋值,再执行staic块
- enum实例比其他静态字段先赋值,因此不允许enum实例初始化时访问static字段
- 执行实例的构造函数前,需要先执行实例代码块
- 所以enum代码块执行顺序是 :实例代码块->enum构造函数->静态字段初始化->静态代码块
- enum实例本质是静态final实例(即enum类的静态字段)
异常(Exception) :程序本身可以处理的异常,可以通过 catch 来进行捕获。
分类
- 分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,即使不处理不受检查异常也可以正常通过编译)。
- 除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。如IO异常
- 静态代码块的异常
- 原则上不允许静态代码块出现异常,如果真的出现,应该直接catch处理掉
- 静态代码块是在类加载的时候就执行了,而执行的过程中,如果出现错误,那么这个类就初始化失败。
- 当类初始化失败时,任何使用该类的代码都可能抛出 ExceptionInInitializerError。
反射
1. 通过反射能绕过访问权限获取私有字段/方法
1 | |
Java 集合
数组和链表的区别
- 数组访问速度快,但插入删除慢,且内存必须连续,可能存在空间浪费或不足无法扩展
- 链表插入速度快,可以动态开辟空间,适合频繁增删改,但是访问速度慢(内存分配、垃圾回收等无需随机访问的经常使用)
- 循环链表的应用:循环队列(体现公平性、轮询)
ArrayList
- 基于Object[]实现,未指定容量时默认为空数组,插入数据时初始数组长度为默认容量10
- 扩容:要插入元素时发现超出当前容量,扩容(newCapacity = oldCapacity + (oldCapacity >> 1)),将原数组拷贝进长度为新容量的新数组中(v.elementData = Arrays.copyOf(elementData, size);)
- clear:将数组中的每个元素都设为null
HashSet、LinkedHashSet、TreeSet
HashSet 的底层数据结构是HashMap。读取顺序是按hash值排序
LinkedHashSet 的底层数据结构是LinkedHashMap,链表维护元素的插入顺序,能按照添加顺序遍历输出
TreeSet 的底层数据结构是红黑树
HashMap单独坐一桌:
- 由数组+链表/红黑树 组成的(链表长>7且数组长度>63,转换为红黑树)。
- 元素是Node<K,V>,红黑树的结点TreeNode继承自Node,使得可以用迭代器遍历map所有结点
- 扩容后,会对链表/红黑树的拆分,根据他们二进制高位(扩容新增那一位)是否为1,会分成2条链表(各自存放到新的map位置),链表长度过长则直接树化
- 总是使用 2 的幂作为哈希表的大小。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。
- hash():
- (h = key.hashCode()) ^ (h >>> 16),右移一半来异或得到hash值
- 通过 (n - 1) & hash 判断当前元素存放的位置
- 如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖;不相同就遍历链表插入链表尾部。
- 红黑树的内部排序基于System.identityHashCode():依据对象初始内存地址计算的一个哈希值(保证了该值不会因为对象内存地址改变而改变)
- 红黑树按照key的compareto方法来排序,如果插入时存在相等节点,则采取是否覆盖的策略
- 核心字段:initialCapacity(初始容量)、loadFactor(负载因子(可以大于1))、threshold(扩容阈值)
- 扩容阈值一般等于Capacity*loadFactor,如果不超过最大阈值的话。当map元素数量>threshold,执行resize()扩容
- loadFactor 负载因子控制数组存放数据的疏密程度,默认负载因子为0.75f。
- 扩容:先创建一个新table,把旧table暂存起来,然后table指向新的空table,遍历旧table的桶把元素迁移到新table(扩容期间get/put操作对新table存在并发问题)
- 线程不安全存在的一些问题:
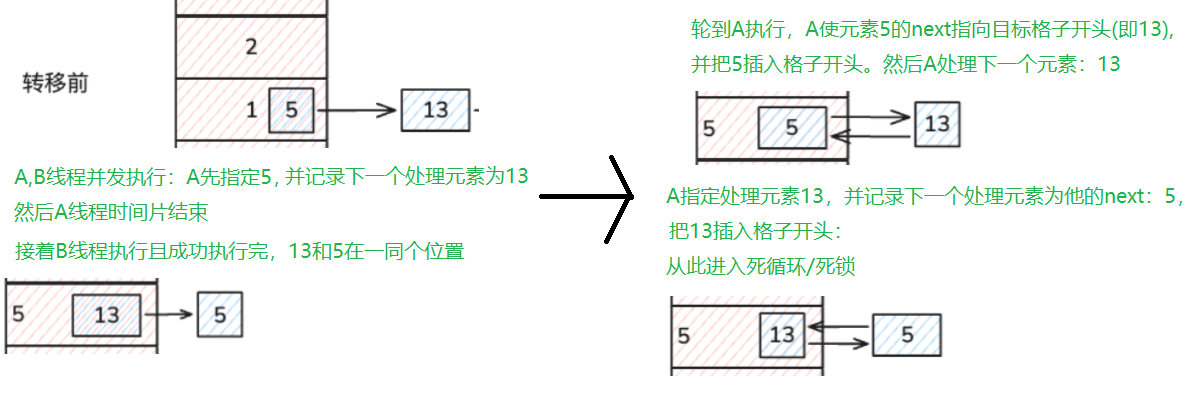
- 扩容会死循环/死锁(JDK7):因为采用头插法,导致链表成为环形链表
- 并发下put元素消失
- get,put并发导致get为null,因为put导致扩容改位置了
- 扩容会死循环/死锁(JDK7):因为采用头插法,导致链表成为环形链表
- 由数组+链表/红黑树 组成的(链表长>7且数组长度>63,转换为红黑树)。
HashTable :线程安全的hash表(主要通过synchronized锁住方法实现,锁粒度太大,性能差)
ConcurrentHashMap
- 加锁:基本是在桶上(table数组的一个结点)加Synchronized,变更操作则是unsafe的cas锁
- 扩容
- 引入了迁移结点ForwardingNode:一个桶被迁移后,把该结点标记为ForwardingNode(key,value均为null,hash值为MOVED(-1),但提供了新table的指向)
- 扩容的核心是transfer迁移方法,
- 第一个执行transfer会创建一个新nextTable
- 对于每个执行transfer的线程,会分配其把旧table的一段连续桶迁移到新table
- 迁移时,从尾巴迁移到头部,每次把复制当前元素插入新表(因此get不用加锁,旧表元素本身不会移动到新表)
- put:如果put的桶是MOVED状态,则执行helpTransfer去帮忙扩容,否则锁桶然后去插入元素
- get:如果get的桶是MOVED状态,说明数据已经迁移到新table,去新table查找,否则查找旧table
LinkedHashMap 继承自 HashMap,并在 HashMap 基础上维护一条双向链表,支持遍历时会按照插入顺序有序进行迭代。
设计模式
- 单例模式(确保一个类只有一个实例)
- 双重检验锁方式实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class A {
private volatile static A uniqueInstance;//全局唯一实例,用volatile修饰,保证线程安全
private A() {}
public static A getUniqueInstance() {//获取实例
if (uniqueInstance == null) {//先判断对象是否已经实例过,没有实例化过才进入加锁代码
synchronized (A.class) {//类对象加锁
if (uniqueInstance == null) {
uniqueInstance = new A();
}
}
}
return uniqueInstance;
}
} - uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为 uniqueInstance 分配内存空间
- 初始化uniqueInstance;
- 将 uniqueInstance 指向分配的内存地址
- 如果不用volatile修饰,执行顺序可能变为1->3->2,那么其他线程获取实例时可能获取一个没有初始化的null实例
- 双重检验锁方式实现
- 代理模式
- 静态代理:在编译时便将代理类变成class文件(一般需要手动增加代理类,除非使用aspectJ)
- 动态代理:运行时,代理类无需编译,直接生成代理类的字节码。无侵入性,无需修改目标类源码。
- JDK动态代理:通过反射机制动态生成代理类(如 Proxy.newProxyInstance())。只能代理实现了接口的类
- CGLIB动态代理:通过字节码生成库(如 ASM)动态创建目标类的子类。只能代理public且非final的方法/类
参考文章
Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
设计模式也可以这么简单
JAVA回调机制(CallBack)详解
解释:为什么枚举类的静态代码块再实例代码块之后?????