

操作系统学习笔记
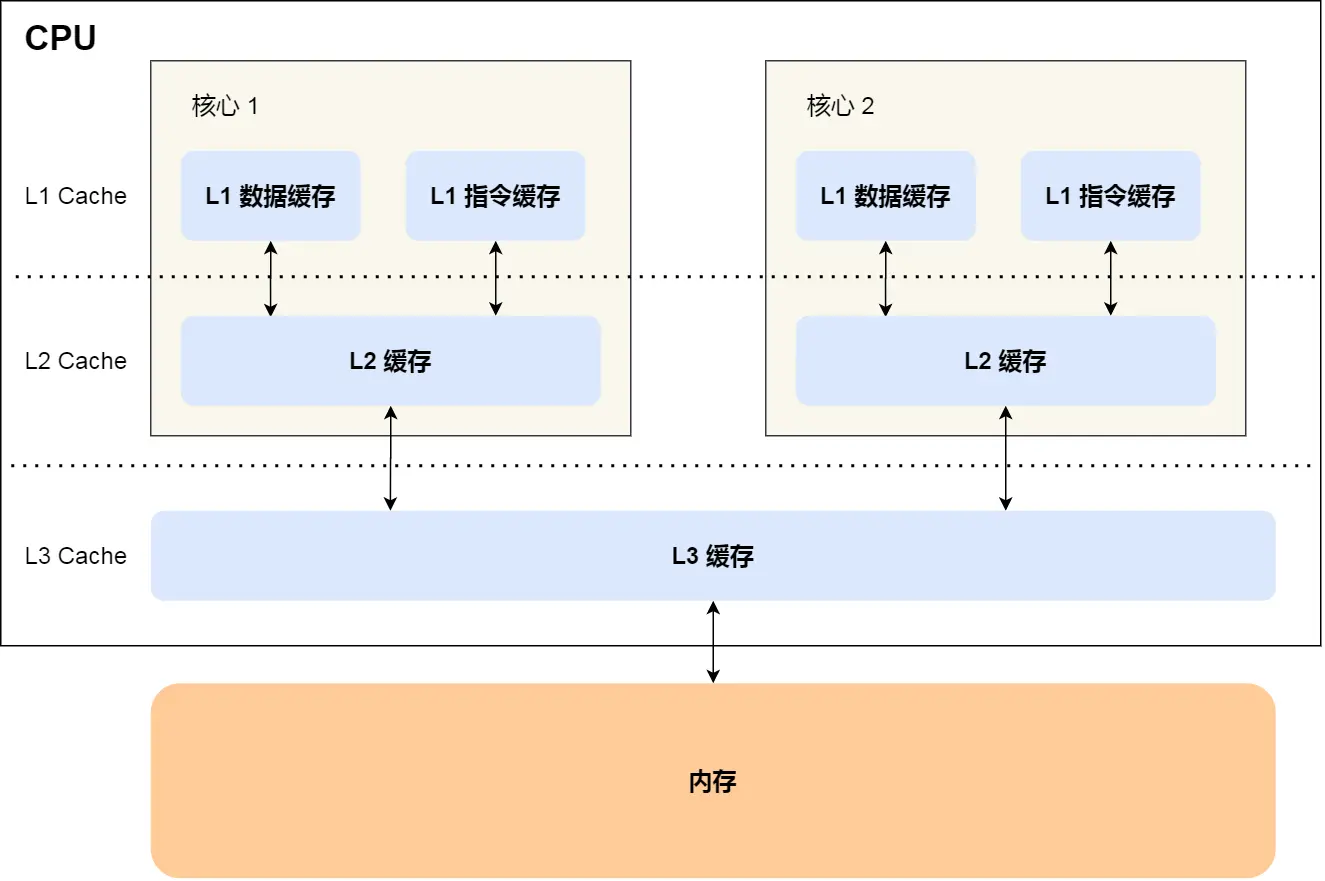
CPU
CPU Cache
- 每个核心都有各自的 L1/L2 Cache,而 L3 Cache 是所有核心共享使用的

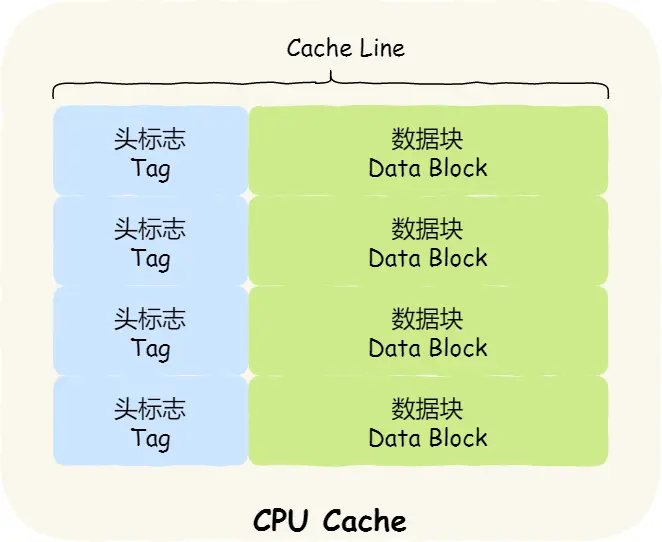
- CPU Cache以Cache Line(一般是64kb)为操作的基本单位
缓存写策略
- 写直达(Write Through):
- 数据不在缓存时,直接写入内存
- 数据在缓存,则写入缓存,并写入内存
- 写回(Write Back)
- 写入数据如果在缓存,则只写入缓存,并标记所属cache block为脏数据块
- 当脏数据块需要被其他数据写入时,把脏数据块写回内存同步
- 数据不在缓存,则先从内存读取该数据所属数据块到缓存(保证后续对该数据块的访问都缓存命中),再写入缓存
- 写入数据如果在缓存,则只写入缓存,并标记所属cache block为脏数据块
多核cpu的缓存一致性
实现了缓存一致性才能保证cpu的原子性操作在多核下保持正确性(cpu的数据读写,cas操作等)
总线 :将计算机的硬件设备联系起来(CPU,存储设备,IO设备等)
- cpu核心,DMA(direct memory access)等会通过总线与其他cpu核心,内存等传输数据
- 总线处理请求是串行化的,其硬件设备上有一套总线仲裁机制(比如先到先处理)来保证只有一个设备持有总线使用权
MESI协议
- 总线嗅探(Bus Snooping) :cpu会监控总线的活动,如果总线有在广播和自身持有缓存数据相关的信息,需要做出响应
- MESI状态机
- 四种状态
- Modified,已修改 :该缓存数据只有该核心持有,且修改过未同步到内存
- Exclusive,独占 :该缓存数据只有该核心持有,与内存数据一致
- Shared,共享 :缓存数据被多个核心持有
- Invalidated,已失效 :缓存数据废弃
- 状态转移策略(每次都需请求总线使用权)
- 读
- 如果总线广播确认没有其它核心持有该缓存,则从内存读取并转为状态E
- 如果有核心持有该缓存且状态M,则会把脏数据刷回内存,同时当前核心从内存读取数据,2个核心该缓存的状态都转为S
- 如果有核心持有该缓存且状态为E或S,当前核心从内存读取,相关核心的缓存状态转为S
- 写
- 如果当前缓存状态是M或E,直接修改该缓存,状态设置为M
- 如果为S,先通过总线将其他核心的缓存状态设为I,再修改缓存并设状态为M
- 如果是I,则先执行读,再执行上述操作
- 读
- MESI只确保了多核心间缓存的一致性,然而线程可以把数据临时存放于寄存器,因此MESI并不能保证并发安全
- 解决办法是使用volatile修饰变量,强制线程每次读写数据都从缓存/内存获取并更新
- 不过cpp的volatile并不保证原子操作,也不能禁止指令重排序,还是存在线程安全问题。线程安全还是需要
std::atmoic保证
- 四种状态
进程管理
进程和线程
进程是资源分配(cpu时间,内存,文件fd等)的最小单位,线程是CPU调度的最小单位
- 进程间的通信方式 :本质是划分一段共享内存缓冲区来交互
- 匿名管道(Pipes) :半双工,用于有亲缘关系的父子进程间或者兄弟进程之间的通信
- 通过调用
int pipe(int fd[2]);会分配2个输入/输出的fd,有有亲缘关系的进程才能通过这2个fd进行通信 - 内核会分配一块固定的FIFO(先进先出)缓冲区用于消息写入/读取,当空间足够时才能写入,当有数据时才能读取,否则都会阻塞
- 通过调用
- 有名管道(Named Pipes) : 半双工,对交互的缓冲区视为一个特殊文件(不会同步到磁盘),有自己的路径名,使得不相关的进程间可通信
- 通过调用
int mkfifo(const char *pathname, mode_t mode)创建有名管道(特殊文件) - 当有进程分别以读/写的方式打开管道时可进行交互(单独打开读/写端会被阻塞)
- 通过调用
- 消息队列 :保存在内核中的消息链表
- 共享内存:需要依靠某种同步操作,如互斥锁和信号量等。
- socket
- 匿名管道(Pipes) :半双工,用于有亲缘关系的父子进程间或者兄弟进程之间的通信
- 进程的调度算法
- 先到先服务调度算法(FCFS,First Come, First Served)
- 短作业优先的调度算法(SJF,Shortest Job First)
- 时间片轮转调度算法(RR,Round-Robin)
- 优先级调度算法(Priority)
- 多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)
- 僵尸进程和孤儿进程
- 子进程exit结束时,内核会释放该进程的所有资源,但其PCB依然存在于系统中。直到其父进程调用wait()才会被释放,以便让父进程得到子进程的状态信息。
- 僵尸进程:子进程终止,但父进程没有调用 wait()导致子进程的 PCB 依然存在于系统中,但无法被进一步使用。该子进程被称为“僵尸进程”。
- 孤儿进程:父进程终止,但子进程仍在运行,未被wait()回收。该子进程为“孤儿进程”。OS会将孤儿进程的父进程设置为 init 进程(进程号为 1),由 init 进程来回收孤儿进程的资源。
- 用户线程和守护线程
- 用户线程:只有所有用户线程结束,JVM才能终止(主线程main结束)
- 守护线程:不会阻止JVM结束
- JVM结束时守护线程会被强制终止,不推荐执行I/O任务,会导致无法正确关闭资源
- 守护线程一般用于后台支持任务,比如垃圾回收、释放未使用对象的内存等
死锁
死锁的四个必要条件
- 互斥:资源必须处于非共享模式,即一次只有一个进程可以使用。
- 占有并等待:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
- 非抢占:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
- 循环等待:进程对资源的等待形成一个环
死锁的预防
- 静态分配策略(破坏占有并等待):进程只有执行前能申请所有资源才执行
- 层次分配策略(破坏循环等待):资源分成多个层次,必须申请到低级资源才能申请高级资源,必须释放高级资源才能释放低级资源(单向性使得不存在循环等待,不会有高级资源申请低级资源的情况)
死锁的避免
- 将系统的状态分为 安全状态 和 不安全状态 ,在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。(银行家算法)
死锁的检测:进程-资源分配图
死锁的解除
- 抢占资源:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
- 逐个撤销涉及死锁的进程,回收其资源直至死锁解除。
死锁的排查思路
- 陷入死锁的线程处于阻塞状态,因此它的堆栈状态会一直不变
- 可以使用
pstack <pid>之类的命令,检测进程pid中所有线程的栈跟踪信息(对线程当前堆栈状态进行快照),如果一个线程的信息一直不变,可能处于死锁中 - 再使用gdb等调试工具查看相应线程的堆栈信息获取结果
- 可以使用
- 陷入死锁的线程处于阻塞状态,因此它的堆栈状态会一直不变
内存管理
基础
- 字节序(大端存储 && 小端存储 :多字节数据的存放方式)
- 大端存储 :高位字节存储在低地址处,低位字节存储在高地址处
- 小端存储 :低位字节存储在低地址处,高位字节存储在高地址处
段页机制
- 分段机制:每个申请内存的程序分配一个适合它大小的连续物理段,程序的虚拟地址通过段表映射到其分配的段上
- 缺点:容易产生外部内存碎片(明明内存够分配给进程,但是不存在足够大小的连续内存段)
- 分页机制:把物理内存分为连续等长的物理页(一般是4KB),虚拟内存也被划分成虚拟页。以内存页为管理的基本单位
- 多级页表的映射(以32位机器为例子)
- 虚拟内存的地址的含义 :[一级页表偏移量(10位),二级页表偏移量(10位),页内地址偏移量(12位)]
- 页表自身也占用一个内存页,页表存放的基本单位是页表项(PTE)(一般是4B,那么一个页表就可以有4KB/4B=2^10个页表项,所以页表的偏移量是10位
- 页表项存储了其代表的下一级页表/数据页对应的物理内存页
- 局部性原理:大多数进程不会使用到4GB(2^32)的所有内存页,只使用少部分。因此进程会永存一级页表,当建立虚拟页和物理页的映射时,才会向os申请物理页并进行映射
- 页面置换 :os没有足够的物理页分配给进程去映射时,就会将已经映射的物理页swap到磁盘的交换区(同时使PTE的映射失效,并向PTE标识置换到磁盘的位置信息,方便后续重新读取)
- 缺页中断(需要切换内核态)
- 软性页缺失(Soft Page Fault):没有建立过映射,向os申请物理页
- 硬性页缺失(Hard Page Fault):映射的物理页被置换了,需要从与新的物理页映射并读取磁盘数据到新物理页上
- 虚拟内存的地址的含义 :[一级页表偏移量(10位),二级页表偏移量(10位),页内地址偏移量(12位)]
- 快表(TLB,Translation Lookaside Buffer):利用CPU cache缓存虚拟页到物理页的映射,避免使用多级页表查询
- 页面置换算法(减少硬性页缺失的产生)
- 最佳页面置换算法(OPT,Optimal)
- 先进先出页面置换算法(FIFO,First In First Out):存在BeLady现象:分配的页面数增多但缺页率反而提高
- 最近最久未使用页面置换算法(LRU ,Least Recently Used):记录页面上次访问时间
- 最少使用页面置换算法(LFU,Least Frequently Used) : 记录页面使用次数
- 多级页表的映射(以32位机器为例子)
- 段页机制:把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
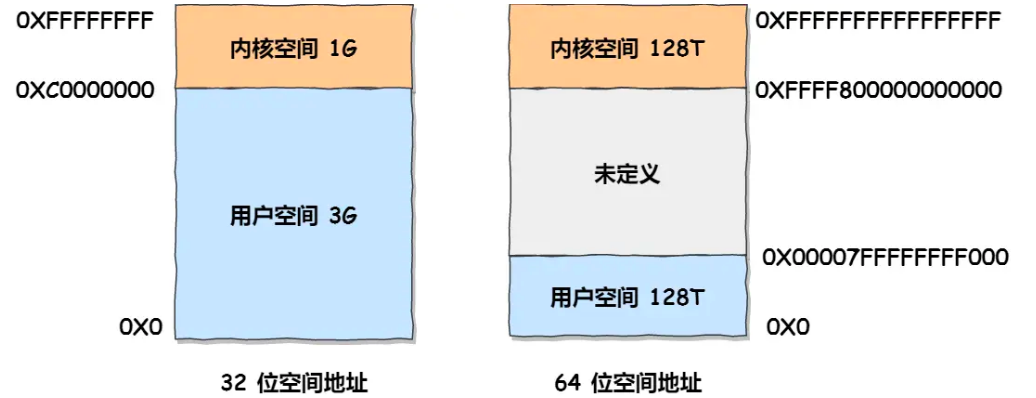
虚拟内存空间
虚拟内存空间大小为2^32 或2^64 ,其中内核空间和用户空间使用的虚拟地址范围不同
每个进程使用独立的用户空间,但是他们指向的内核空间是同一个
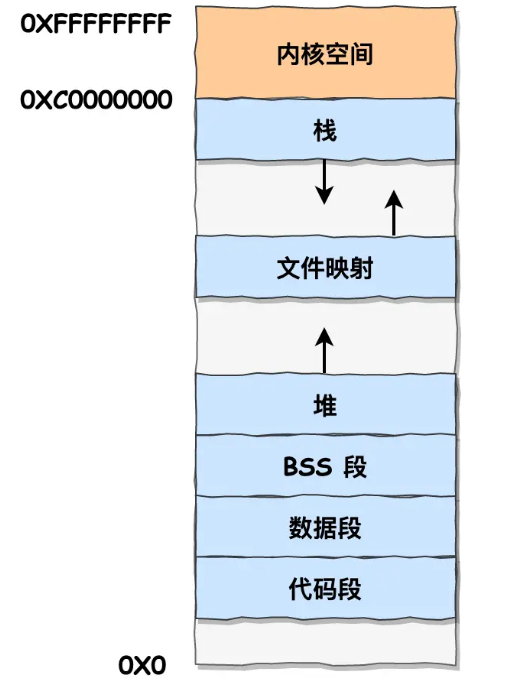
用户进程空间又被划分为如下结构
- 代码段(.text) :只读,存放可执行二进制代码文件,字符串字面值和只读变量
- 数据段(.data)/BSS段(.bss)(Block Started by Symbol)
- 数据段存放已初始化的全局变量和静态变量
- BSS段存放未初始化的全局变量和静态变量(设置为零值)
- 在编译器和链接器生成可执行文件时,就已经计算好了上述变量所需空间
- 堆(.heap) :动态分配内存(向高地址增长)
- 内存映射段(mmap,文件映射与匿名映射区) :内核将硬盘文件直接映射到内存,或进行匿名内存映射用于存放程序数据
- 避免了内核态与用户态间的数据拷贝(零拷贝)
- 多进程间可共享映射的只读文件(动态共享库等)
- 栈(.stack) :存放函数的上下文,局部变量/对象,函数参数等(向低地址增长,有指定最大上限,多则栈溢出)
malloc-free :C提供的动态内存分配/释放方法(库函数)
malloc():根据申请内存大小,有2种执行方式/系统调用(必须涉及用户态到内核态的切换)brk():malloc内部会维护一个内存池(空闲链表管理,减少系统调用次数),当用户通过malloc申请内存小于指定值(128kb)时,会从内存池分配- 如果内存池空间不够,则会调用系统调用
brk(),从堆移动堆顶指针进行分配 - 缺点就是容易产生内存碎片(中间释放的内存很难还给堆),因此管理的内存不会太大
- 如果内存池空间不够,则会调用系统调用
mmap()(Memory map) :用户分配的内存大于指定值时调用,从文件映射区分配一块内存用于匿名映射(系统调用)
realloc():用于尝试改变原本指针指向的内存大小- 如果指针所指内存是否有足够的连续空间,则原地设置新的内存大小,并且返回原来的地址指针
- 否则申请一片新内存,并把原本内存数据拷贝到新内存
内存分配机制
- 进程向os申请资源时,分配的是虚拟内存,因此申请大小只要不超过虚拟内存均可(即用户空间)
- 在访问不存在的虚拟页数据时,会产生缺页中断去获取物理页来映射
- 如果内存不够,并开启swap机制,则会把部分数据页swap到磁盘的交换区(Swap Space,以提供空余数据页
- 如果交换区也不够,最终则是OOM(out of memory)
文件系统
基础知识
- 文件系统中文件的构成
- 数据(Data):即文件名与文件实际数据
- 元数据(Metadata):记录文件相关信息,通过i-node(Index Node) 这个数据结构维护(文件系统通过i-node唯一标识一个文件),维护信息如下
- i-node的id编号、文件类型(普通文件、目录、符号链接(软链接)、设备文件(如 /dev/null)等)、硬链接计数等
- 文件所有者与所有者权限
- 文件相关时间戳 :最后一次访问时间、最后一次修改时间、上述i-node信息最后一次被修改的时间
- 指向文件数据块在磁盘位置的指针
- 元数据不和文件数据存放在一起,而是集中存放在专门的区域,方便快速查找i-node
- i-node被内核加载到内存时会封装为v-node(Virtual Node)
- 硬链接和软链接:每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。
- 硬链接(Hard Link,ln命令):不能跨文件系统,硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的
- 软链接(Symbolic Link,ln -s命令):能跨文件系统,类似快捷方式,可指向空文件/目录
- 磁盘调度算法
- 先来先服务算法(First-Come First-Served,FCFS)
- 最短寻道时间优先算法(Shortest Seek Time First,SSTF):优先选择距离当前磁头位置最近的请求进行服务
- 扫描算法(SCAN):扫描到边界才转向
- 边扫描边观察算法(LOOK):改进SCAN,移动方向上无请求,立即改变磁头方向
- 循环扫描算法(Circular Scan,C-SCAN):只按照一个方向扫描
- 均衡循环扫描算法(C-LOOK):改进C-SCAN,移动方向上无请求,立即让磁头返回
文件IO
文件描述符(file description)
- Linux下一切皆文件。linux中的资源都可以被抽象成fd进行io操作
- 当我们使用
open()打开一个资源时,会返回一个fd用于后续操作这个对应文件(对一个文件open多次,则有多个fd对应这个文件) - 每个进程都会维护一个文件表,文件表的每个文件表项(Open File Table Entry)以fd为索引,记录了该fd操作的文件的动态状态和访问权限
- 文件偏移量(File Offset / Seek Pointer) :实现文件的顺序访问,记录文件下次读写的默认开始字节(可以通过
lseek()来修改) - 访问模式(Access Mode) :操作目标文件的权限和模式,如
O_RDONLY(只读)、O_WRONLY(只写)、O_RDWR(读写)、O_APPEND(追加写) - 文件状态标志(File Status Flags) :控制I/O行为
O_NONBLOCK(非阻塞 I/O):读写操作会立即返回而不是等待数据O_SYNC(同步写入):类似于调用fsync(),要求每次写入都同步到磁盘
- 指向文件对应的v-node的指针 :用于获取文件在磁盘上的元数据信息
- FD引用次数 :通过
fork()等方式可以多个进程使用一个fd,此时fd对应文件表项的引用次数会增加,调用close()时会减少引用次数,当引用为0时才会释放文件表项相关资源
- 文件偏移量(File Offset / Seek Pointer) :实现文件的顺序访问,记录文件下次读写的默认开始字节(可以通过
open()系统调用流程- 根据文件路径查找到i-node,并把i-node封装为v-node放入内存
- 创建文件表项,并将文件表项的指针指向v-node
- 创建fd来索引上述的文件表项,最终返回fd
IO操作与多路复用
文件同步
- 延迟写(delayed write)
- os调用
write()实际只是把数据写入缓存页,即使再调用close()也只是释放了fd,并不保证写入的缓存页刷入磁盘 - 内核会把io刷盘任务放到io队列,io调度器会采取一定的策略来执行io队列的任务(以减少磁头寻道时间等)
- os会在适当时间把脏页刷入磁盘,或者用户显式调用文件同步命令对数据刷盘
- os调用
- 常见的文件同步命令
sync():将文件系统的所有脏页加入io队列后不阻塞等待直接返回update或flush之类的后台守护进程会周期性地调用,以保证脏页不在内存停留太久
fsync(fd):将指定fd的所有数据和所有元数据相关脏页都加入到io队列,并阻塞等待到刷盘完成- 因为2类数据磁盘存放位置不同,因此有2次刷盘io
fdatasync(fd):类似fsync(fd),但只强制将文件数据和必要的元数据(保证数据可检索所需的元数据)刷盘- 如果文件修改前后占用大小没有改变,则不会同步元数据,避免多余的一次io同步
msync(addr, len, flags):类似fsync(fd),用于同步mmap()等建立的内存映射文件,可以更详细的指定同步策略(如同步的范围,是否异步等)