

网易互娱二面(4.11)
项目
feed推送如何实现
在线用户表如何维护
热度排行榜如何维护
八股
hashmap如何扩容,是一次性的操作吗,扩容途中CRUD怎么解决
服务端如何维护tcp链接,半连接队列,全连接队列
tcp队头阻塞是什么
如果前面的tcp包丢了,继续下去会发生什么
tcp慢启动和拥塞控制,如何识别网络波动和超时
http状态码,502,500是什么
http2解决了什么问题
http3了解吗
redis rdb如何快照,主线程有操作怎么办,
- Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本(压缩的二进制数据,文件小,恢复数据直接解析文件即可),一定时间内数据变换越快,越快触发RDB持久,默认RDB fork 出一个子进程执行快照任务(但每次快照全部数据还是慢)
- BGSAVE使用子进程执行(默认使用),SAVE使用主线程执行,会阻塞其他命令
- BGSAVE快照核心:fock的写时复制
- 写时复制存在的问题:如果修改大key,主进程需要大量时间阻塞来复制新内存页
aof又是怎么做的
- AOF 持久化会把所有更改 Redis 中的数据的命令写入到 AOF文件(执行完命令再写入,避免写入时阻塞当前命令)
- 持久化方式(fsync策略) appendfsync always:每次write写到系统内核缓冲区后,会立刻把数据同步到磁盘的AOF文件 appendfsync everysec:write完立即返回,fsync每秒同步一次 AOF 文件 appendfsync no:write完立即返回,让操作系统决定何时进行同步
- 工作流程
- 所有的写命令会追加(append)到 AOF 缓冲区中
- 再将 AOF 缓冲区的数据写入(write,系统调用)到系统内核缓冲区
- 根据文件同步策略(fsync,系统调用)将系统内核缓冲区内容同步到磁盘
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行文件重写(读取所有缓存的键值对数据,并为每个键值对生成一条命令),达到压缩的目的
- 子进程执行重写:利用fock的写时复制,子进程和父进程共享内存,减少内存复制开销。同时保证主进程修改数据时子进程的重写不受影响
- 期间服务器的命令则记录在重写缓冲区
- 新日志重写完后,主进程收到信号,把重写缓冲区的内容追加到新aof文件,然后覆盖旧aof文件
- 当 Redis 重启时,可以加载 AOF 文件进行数据恢复(重启加载,load),恢复需要依次执行每个写命令日志的命令,速度慢,因此不建议单独使用
- AOF 校验机制:校验和(checksum,使用CRC64),checksum存在于AOF文件尾部来检验
mysql redolog的两阶段提交,redolog提交是指直接刷新到磁盘吗
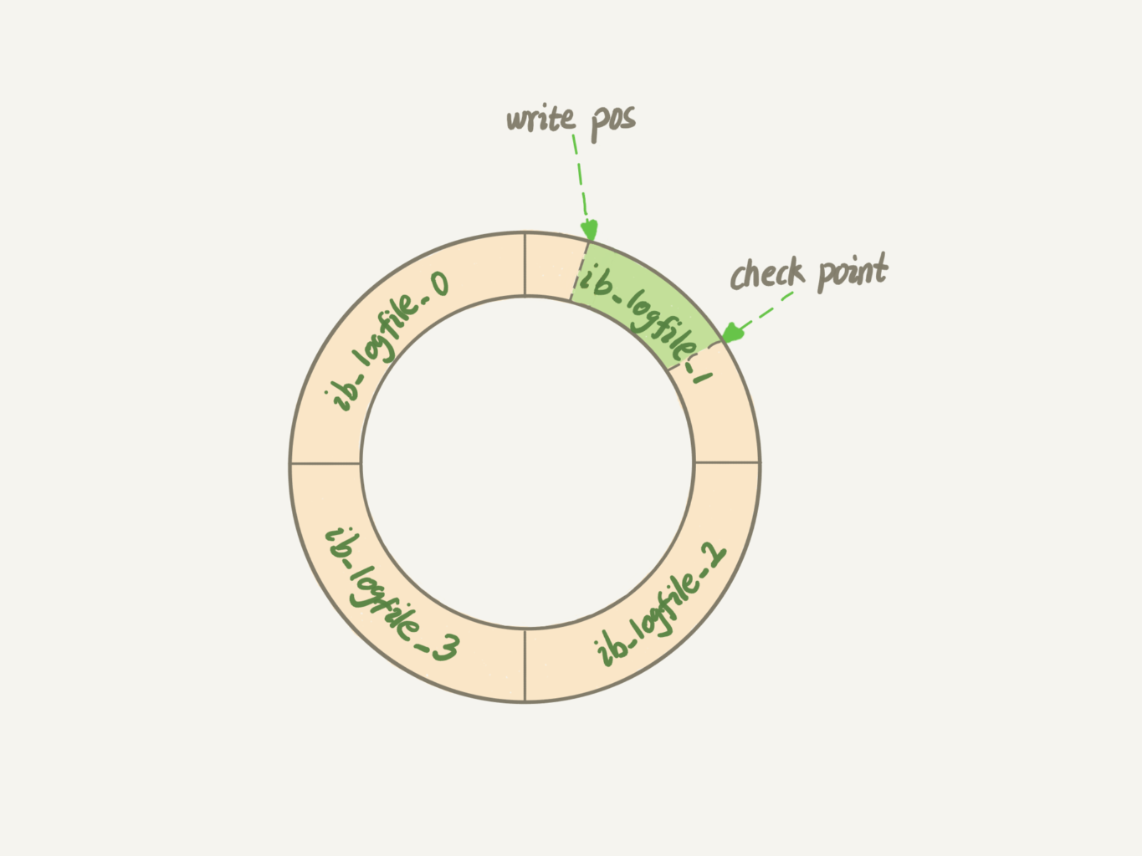
- redo log文件
- 一般配置一组4个文件,循环写入(write pos和check point)
- 文件内容是只写到内存,还未刷入磁盘的数据(保证宕机时可以用来重做)
- 如果redo log写满,此时必须阻塞mysql,把部分脏数据页刷盘,从而释放redolog

- redolog刷盘策略:一般都是选择提交事务时直接把redolog buffer的内容直接刷盘到redolog文件,而不是留在redolog buffer或page cache(os的文件缓存)
- redo log文件
mysql 的lru
linux的写操作是不是总是原子性,如果一个进程在读文件,另一个把文件删了,会发生什么
SQL题
- 一道SQL需要加什么锁
场景题
数据量很大如何维护排行榜
大数据量如何进行一个distinct的count,粗略统计即可